



If you look at how a scientist or a data scientist has used their computer from 2000 until 2025 you would likely not recognize toolsets as they have changed across science and industry however the SQL database abides. In 2008 I wanted to study chaos theory and so I worked for a bit on MATLAB code calculating neuron action-potentials. There was active discussion in the lab about python and how it wasn’t ready for science (2008 was when pandas first started being developed so the scientific python ecosystem was still in very early days). In 2009 I worked on a project programming FPGAs with LabVIEW to control photomultiplier tubes to detect muons. I then spent a semester learning C/C++ so that I could use ROOT, an interactive interpreter environment for C/C++ that high energy physicists use. I remember going to a conference in 2011 and hearing about JAVA for physics simulations. Meanwhile I had been reading about the advent of noSQL, databases that eschew the typical relational structure instead focusing on key-value stores. The logic at the time was performance was more important than any kind of data consistency since data had transformed from financial transactions, purchases, and website registrations to likes, photo uploads, and tweets. Throughout all of this time SQL was and continues to be the defacto database system that was used across industry.
Around 2011 a software developer friend of mine convinced me that I needed to learn python and SQL at the same time. That python and SQL together would change my working life and that data science was becoming the next thing. And that I should definitely ignore the noSQL crowd for the time being because I needed to at least learn why SQL was so great before learning why it was bad (good logic for lots of solutions in search of a problem). So I took a course in database systems at Georgia State University taught by Raj Sunderraman. The course covered both theory and application of SQL databases. I had to read the original Codd papers describing the relational paradigm, we learned the underlying relational algebra, but most of the class was building software applications that respected a given database schema that we designed. You can see here a very embarassing CLI storefront I built for a class project, I guess the database itself is lost to time. At the time I had no idea how important SQL would become to me and all of the work that I would end up doing into the future, I only had my friend’s advice that learning SQL was great.
After finishing my masters degree I worked on a variety of projects that all used SQL databases including clickstream processing of Coursera data for video lectures, a data sharing model for physics education research that utilizes a lot of relational concepts, I organized an educational data mining internship where students learned SQL and machine learning and applied it to research questions, and my PhD where I rebuilt a 700+ table production database used by an American university into an analytics database used to predict what students would do at university like dropping out or changing their majors. The original production database was fascinating including information about all sorts topics from office assignments for professors to grass mowing schedules in addition to the more relevant student information.
Suffice to say, I quite enjoy building and using databases. I find that by building a database you create a structured opinion about how you plan to pursue a line of research questioning. By using SQL databases you also align yourself more closely to industry where they are used constantly. And I truly believe that using databases more frequently in our research we would accelerate results discovery. But maybe I should tell a bit about a database in order to make this post useful to all my readers.

Relational Databases
If you have ever used a JOIN or MERGE operation in python using pandas then you have used an idea that came from relational databases. Relational databases are software systems designed to store data. Essentially, all databases contain a set of tables, and the relationships between the contents of each table. This is separate from other ways of storing data such as a folder hierarchy of data files, as these database systems enforce control on their data using a user specified schema (the data held in the database is forced to conform to a specific structure), the data can be queried using a special query language called SQL (which stands for Structured Query Language not special query language), and the database will enforce things like ACID compliance. Traditionally a database insists on strict relationships instead of fuzzy ones, that is something either is or is not related to each other, but these days there is lots of technology to handle fuzzy relationships as well. But overall, I think the most important concepts for a scientist to understand about databases are schemas.
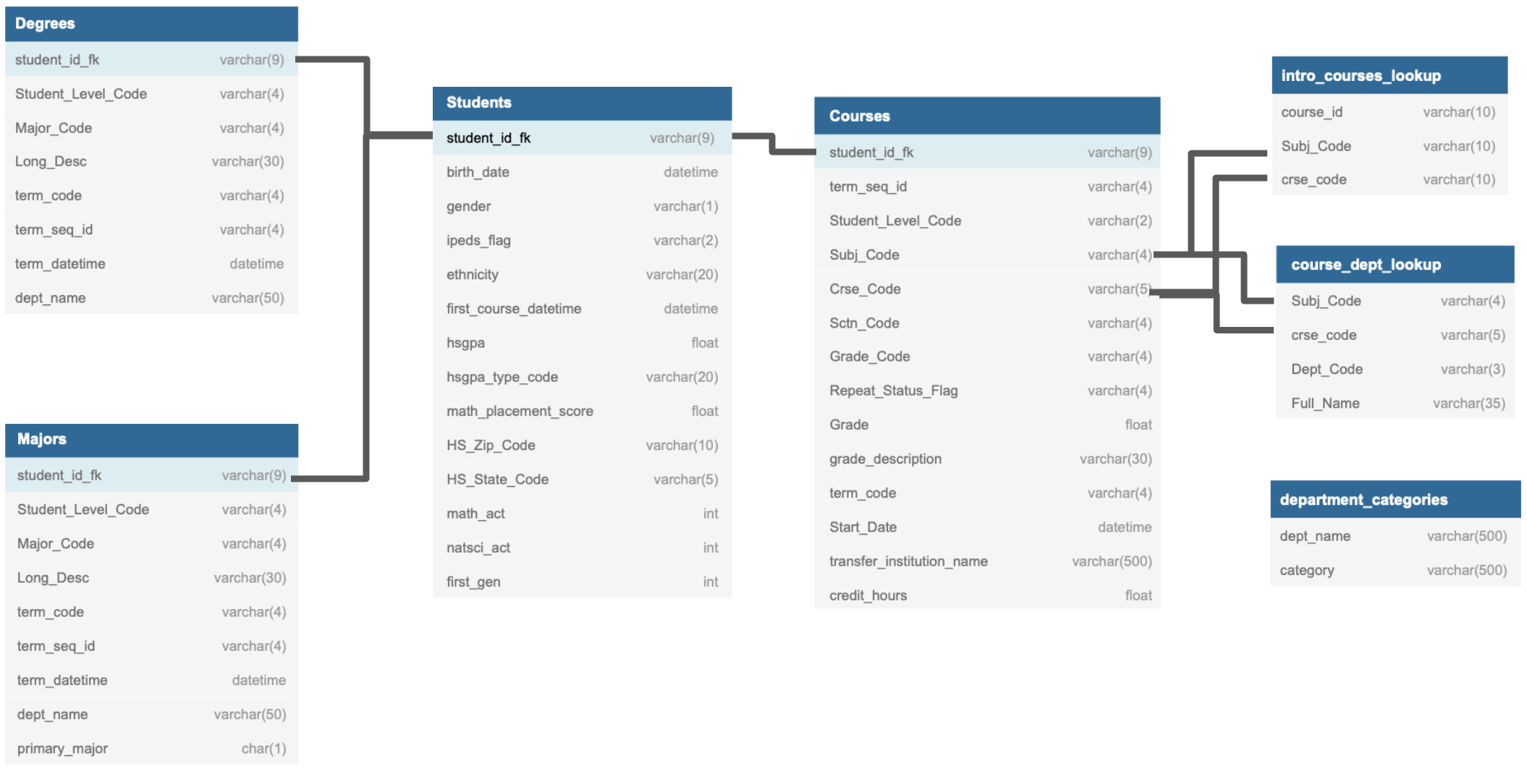
A schema is the description for how data connects to other data in a database. The schema can set dependencies, it defines the structure of each table (e.g., the type a variable that a column can store), how that table connects to other tables using primary/foreign key relationships, and what kind of data the table can store. Schemas insist on conforming your data to their structure, software must be written to take whatever data you have and transform it to this schema so that it can be queried. Once your data is inside of a database you can write powerful queries using SQL (the query language this is all named after).
SQL is an easy to read query language that is baked into any SQL database software system. It allows you to write queries against the data to build a dataset from the underlying database. In the example from my PhD, you could produce a dataset for all of the students ever registered as a physics major with a simple query like:
SELECT *
FROM Majors
JOIN Students
ON Majors.student_id_fk = Students.students_id_fk
WHERE Majors.Major_Code = 'PHYS'This will produce an entire dataset describing these students. Coupled with a pandas.read_sql statement and you already have a very powerful analytics engine at your finger tips.
I do not think that a SQL database can solve every problem although modern SQL databases seem to be able to do anything. Postgres has both an excellent time series engine and geospatial engine. Understanding SQL gives you a powerful toolset for data mining. You can take piles of unstructured data, define a schema that you believe will enhance analytics of that pile, build data pipelines that transform that data into your schema, then do statistics, visualizations, and build models against your new analytics database.
But I do think the lessons of how data relates to other data is an excellent tool for any scientist to have in their belt. The only downsides is that can require time and you need a good amount of data. There is little reason to build a database if you only have 1 spreadsheet. However I encourage scientists to build more databases of the data they collect and make them more freely available. By “productionizing” your data storage, you make your data more accessible to others.